我把一个 AI 零代码项目上线并改造了
2026年6月8日
我把一个 AI 零代码项目上线并改造了
半年多前,我跟着 AI 零代码应用生成平台 完成了项目的大部分功能并上线了。教程版本已经跑通了从自然语言描述到代码生成、预览和部署的基本流程。最近闲来无事,我又重新捡起这个项目,从界面、生成过程、代码查看、React 构建和线上稳定性等方面做了几轮改造。
在线体验:https://zerocode.1000ye.top
GitHub 后端仓库:https://github.com/X1aoM1ngTX/zerocode-backend
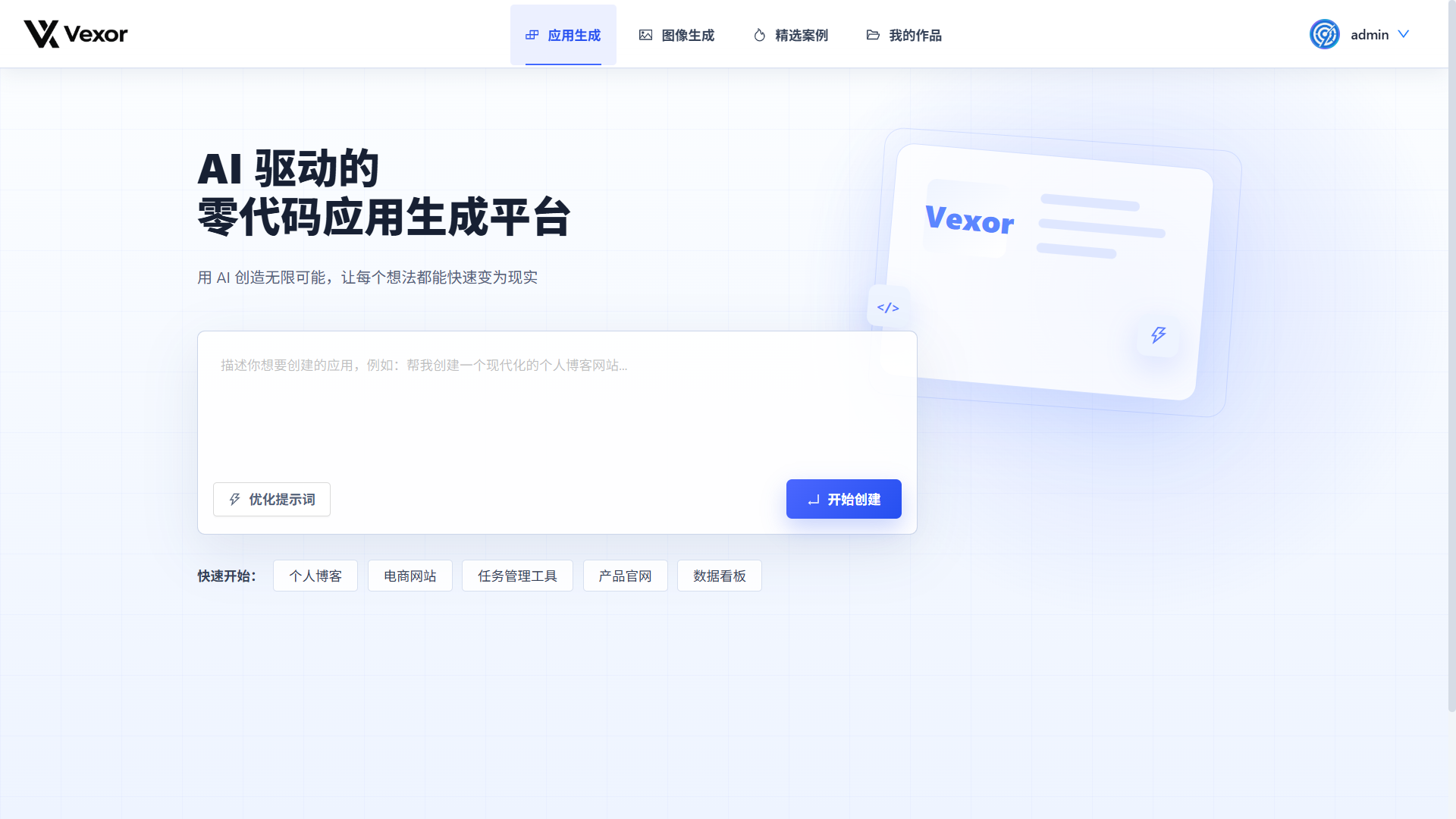
Vexor 首页:输入一段应用描述,就可以开始生成项目。
这篇文章不准备逐行讲代码,主要记录我为什么要做这些改动、具体是怎么处理的,以及项目从“能运行”到“能上线”过程中遇到的一些实际问题。
先把前端界面重新整理了一遍
最早的页面主要围绕功能实现,能用,但整体比较像后台管理系统。不同页面的布局、颜色和交互方式也不够统一,用户从首页进入应用生成页面时,会有比较明显的割裂感。
这次调整前端时,我没有一开始就让 AI 直接修改代码,而是先整理了一张比较粗糙的草图。草图里不关注字体、颜色和间距,主要标出每个页面需要展示什么,以及不同区域之间的关系:
- 首页需要突出应用描述输入框和常用模板
- 登录、注册和重置密码页面保持统一
- 应用生成页面采用左右布局,左侧负责对话,右侧负责预览和代码
- “我的作品”和“精选案例”复用相同的卡片布局
- 顶部导航在主要页面中保持一致

最开始整理的页面草图,重点是确定信息结构和功能区域。
有了草图后,我把它交给 ChatGPT,让它根据现有品牌 Logo、蓝紫色主色调和 AI 产品的定位生成一版更完整的视觉设计。生成的设计图补充了字体层级、卡片样式、背景效果和深色应用工作区,也让我能在真正改代码前先判断整体方向是否合适。
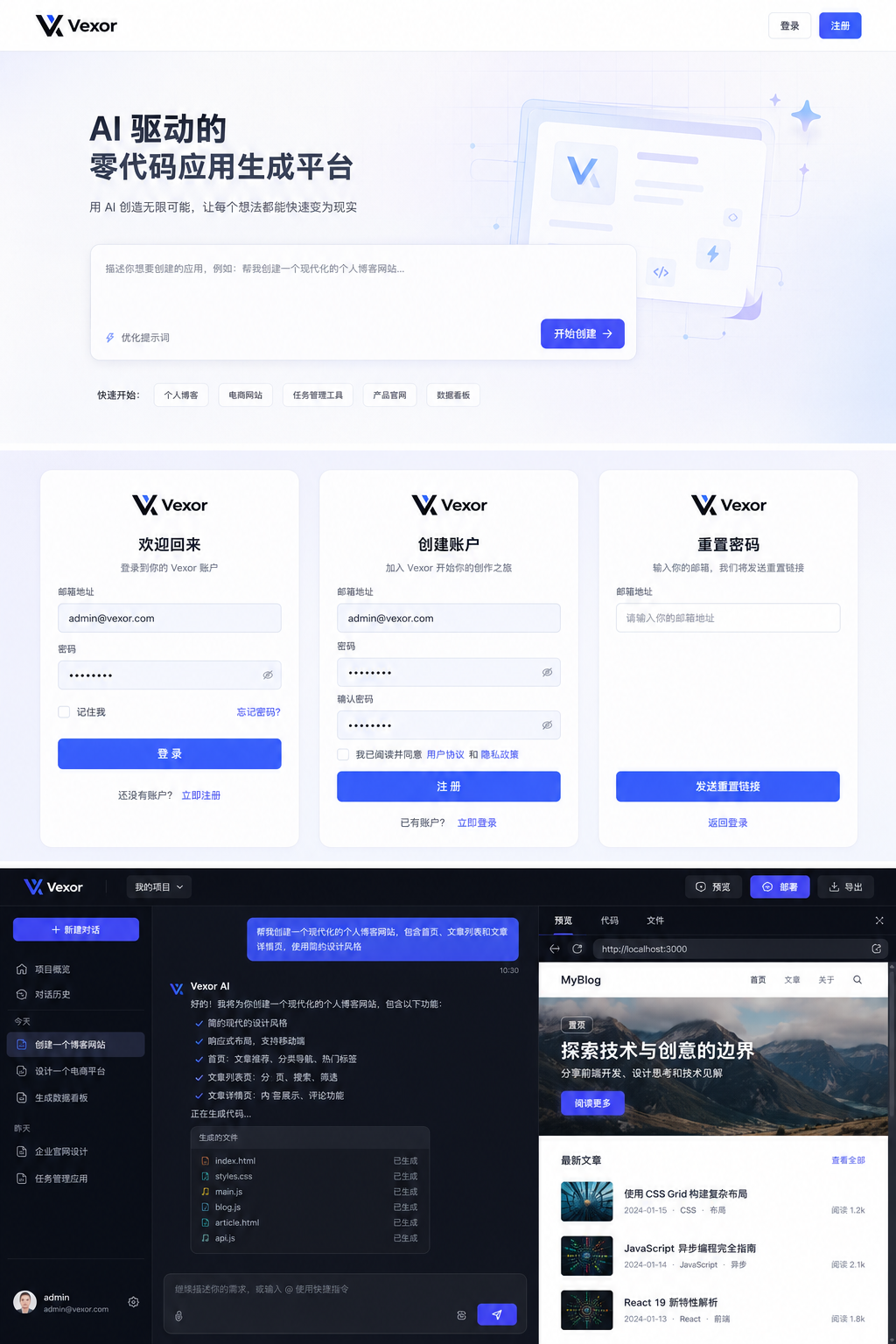
ChatGPT 根据草图生成的视觉方案,包含首页、认证页面和应用工作区。
设计方向确定后,我再把草图、设计图和现有项目代码一起交给 Codex,让它按照 Vue 3 和 Ant Design Vue 的现有结构逐步落地。这个过程中并不是直接照着图片还原,而是需要结合真实功能继续调整:
- 将设计图中的颜色、圆角和阴影整理成全局 CSS 变量
- 保留已有接口、权限判断和页面路由,避免只改外观却破坏功能
- 把重复的加载状态、空状态和错误处理整理成公共组件与组合式函数
- 根据真实内容长度调整布局,并补充移动端适配
- 将应用生成页的对话、预览和代码区域接入实际数据
这套流程里,草图负责表达我的想法,ChatGPT 帮助探索视觉方向,Codex 则负责结合现有代码完成实现。最终页面没有完全照搬设计图,但整体布局和视觉风格有了统一的参考,也减少了边写代码边反复试样式的时间。
增加提示词优化和文生图
很多用户第一次使用 AI 生成应用时,只会输入一句比较简单的描述,比如“帮我做一个个人博客”。这种表达没有问题,但里面缺少页面结构、视觉风格和具体功能,模型只能自行猜测,最后生成的结果往往比较普通,也未必符合用户真正想要的方向。
所以我在首页和应用对话页增加了提示词优化功能。用户输入简单想法后,可以先让单独的提示词优化模型补充页面组成、交互方式和设计要求,再决定是否使用优化后的内容开始生成。
例如,“帮我做一个个人博客”可以被补充为包含首页、文章列表、文章详情、分类筛选、响应式布局和视觉风格的完整需求。它不是替用户决定所有细节,而是帮助用户把脑海里比较模糊的想法表达清楚。
这部分使用了独立的系统提示词和模型配置,没有直接占用代码生成模型的上下文。优化完成后,结果会回填到输入框中,用户仍然可以继续修改,而不是立刻开始生成。
相关实现主要在:
vexor-frontend/src/pages/HomePage.vue
vexor-frontend/src/pages/app/AppChatPage.vue
vexor-backend/src/main/java/com/xm/vexorbackend/ai/PromptOptimizerService.java
vexor-backend/src/main/resources/prompt/prompt-optimizer-system-prompt.txt
除此之外,项目还接入了阿里云 Z-Image-Turbo,增加了单独的文生图页面。除了正向提示词,页面还支持负向提示词、图片尺寸和随机种子等参数,方便重复生成或控制结果。
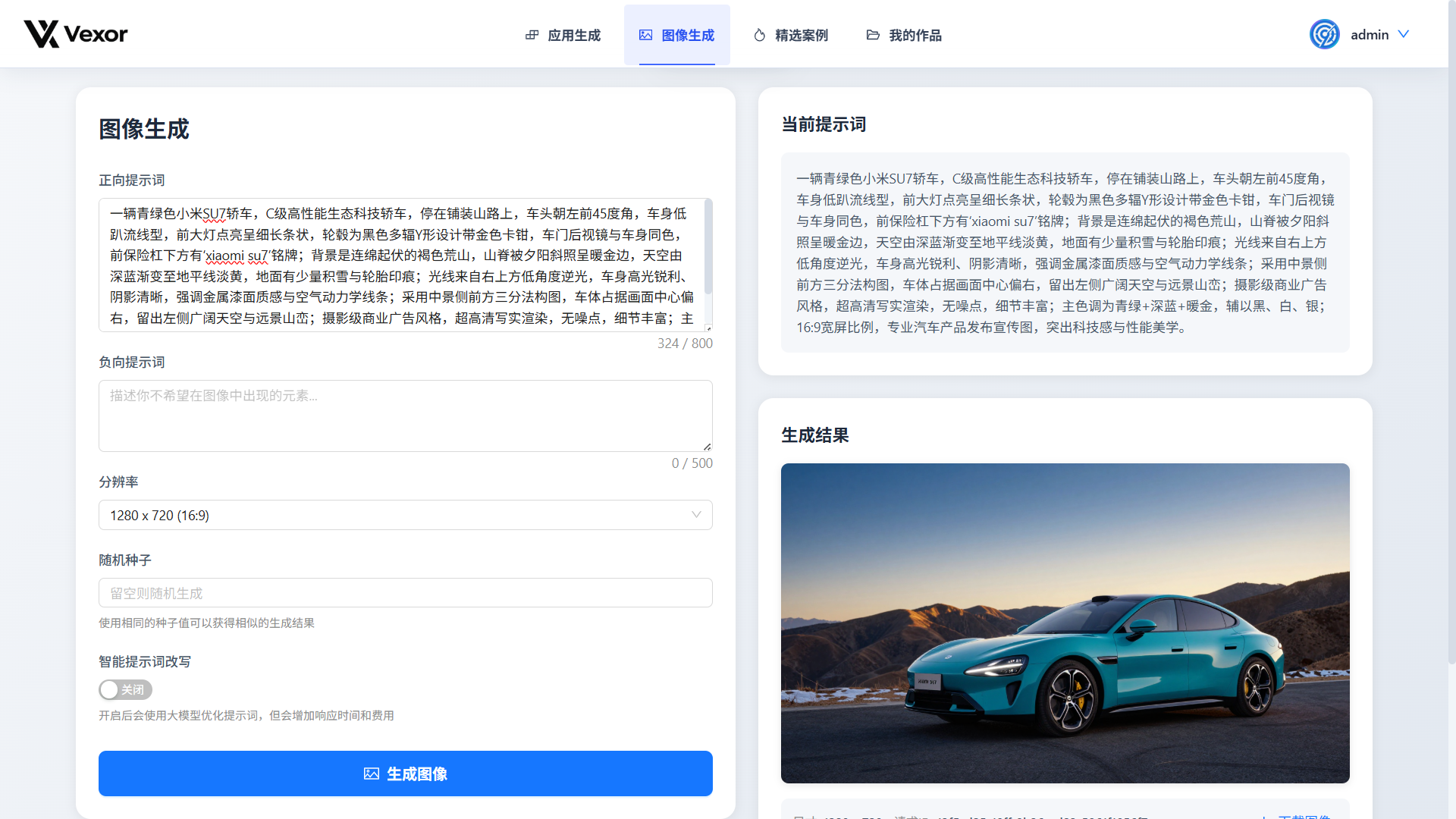
文生图页面会同时展示当前提示词、生成参数和最终图片。
文生图接口调用成本比较高,也容易被频繁请求,因此后端给这个接口增加了登录校验和 IP 限流。目前同一个 IP 每小时最多生成 8 张图片,避免接口被持续调用后产生不可控的费用。
让代码生成过程真正“看得见”
最近一次改动最大的地方,是应用生成页面。
之前生成代码时,如果生成的是 Vue 或 React 项目,AI 的回答和代码内容会混在一起返回。一条消息中可能同时包含项目说明、十几个文件的路径以及完整代码,数据量很容易超过 MySQL TEXT 字段的存储上限,最终导致聊天内容被截断或保存失败。
即使成功保存,把所有代码都塞进聊天记录也不方便使用。用户需要在一段很长的 Markdown 中反复滚动,才能找到某个组件;刷新页面后,前端还要重新渲染整段代码,消息越多,页面越容易卡顿。
这次改造的思路,是把“聊天内容”和“项目文件”分开处理:
- 聊天区域只展示生成计划、执行过程和简短说明
- AI 生成的代码直接保存到对应应用的项目目录
- 前端需要查看代码时,再通过文件接口按需读取
- 文件发生创建、修改或删除时,通过流式事件及时更新页面
这样一来,数据库不再承担保存整套项目源码的工作,聊天记录也更容易阅读。代码则按照真实项目结构保存在磁盘中,后续构建、部署和下载都可以直接复用这些文件。
现在应用页面增加了独立的代码工作区。左侧文件树展示项目目录结构,右侧显示当前选中的文件内容。点击不同文件时,前端只请求对应文件,并根据 .vue、.tsx、.css 等扩展名判断语言,再通过 highlight.js 进行语法高亮。
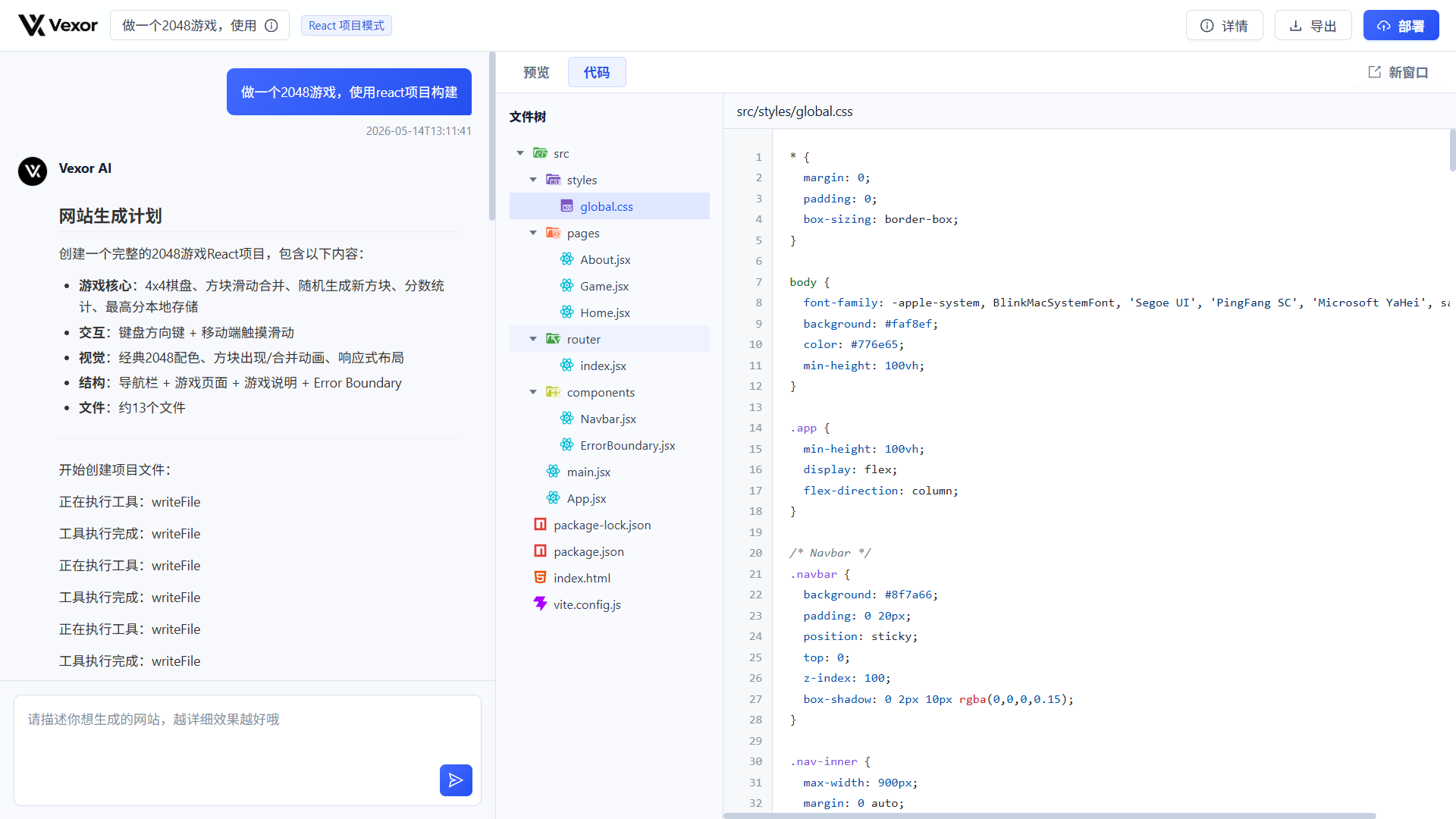
应用生成页面可以同时查看 AI 回复、项目文件树和具体代码。
前端的文件树使用递归组件实现。目录节点可以展开和收起,文件节点会记录完整相对路径;图标则按照文件名、扩展名和目录名称匹配,让 Vue、React、TypeScript、样式文件和配置文件更容易区分:
vexor-frontend/src/components/AppFileTreeNode.vue
vexor-frontend/src/pages/app/AppChatPage.vue
后端则增加了单独的文件服务,用来扫描应用目录、组装树形结构和获取文件内容:
vexor-backend/src/main/java/com/xm/vexorbackend/service/AppFileService.java
vexor-backend/src/main/java/com/xm/vexorbackend/service/impl/AppFileServiceImpl.java
vexor-backend/src/main/java/com/xm/vexorbackend/model/vo/AppFileNodeVO.java
vexor-backend/src/main/java/com/xm/vexorbackend/model/vo/AppFileContentVO.java
读取文件看起来很简单,但实际还需要处理一些边界问题:
- 校验当前用户是否有权查看对应应用
- 将用户传入的相对路径解析到应用目录下
- 阻止
../等路径穿越,避免读取服务器上的其他文件 - 忽略
node_modules、构建产物等没有必要展示的目录 - 对文件不存在、读取失败等情况返回明确错误
拆分之后,聊天、代码查看、项目构建和部署各自负责自己的事情,整个生成页面也更接近一个简单的在线开发环境,而不再只是一个展示 AI 回复的聊天窗口。
把流式回复改成更明确的生成事件
AI 生成一个完整项目通常需要几十秒,复杂项目还要等待依赖安装和构建。如果前端在这段时间里只显示一个加载动画,用户很难判断 AI 还在工作、构建正在进行,还是连接已经断开。
为了解决这个问题,我没有只把回复文本逐字推送到前端,而是在原来的 SSE 流式接口上增加了一套生成事件。后端在执行不同操作时发送对应消息,前端则根据事件类型更新聊天区域、代码内容、文件树和预览状态。
目前主要包括这些事件:
assistant_message AI 正在回复
tool_call AI 正在调用工具
file_start 开始生成文件
file_delta 文件内容更新
file_done 文件生成完成
file_delete 删除文件
build_status 项目构建状态
preview_ready 预览已经可用
generation_error 生成失败
done 全部完成
Vue 和 React 项目主要通过文件工具创建和修改代码,工具执行时可以直接转换成对应事件。HTML 和原生多文件项目的返回格式不同,代码仍然包含在模型持续输出的 Markdown 文件块中,因此后端又增加了一个文件块流式解析器。
这个解析器不能简单地按每次收到的字符串查找代码块,因为模型返回的一个 chunk 可能只包含半行内容,甚至刚好截断在文件路径或代码块标记中间。它需要保留尚未解析完成的内容,识别完整文件块后,再依次生成 file_start、file_delta 和 file_done 事件,并把代码保存到磁盘。
这部分主要修改了:
vexor-backend/src/main/java/com/xm/vexorbackend/ai/model/message/
vexor-backend/src/main/java/com/xm/vexorbackend/core/AiCodeGeneratorFacade.java
vexor-backend/src/main/java/com/xm/vexorbackend/core/handler/FileBlockStreamParser.java
前端收到文件事件后,会实时更新当前代码和已生成文件列表;收到构建状态后,会提示正在构建 Vue 或 React 项目;收到 preview_ready 后,再刷新右侧预览。连接异常和业务异常也会单独处理,避免把正常结束误判成生成失败。
改完以后,用户不需要一直盯着加载动画,可以看到 AI 正在创建哪个文件、项目是否正在构建,以及预览什么时候可以打开。对我自己来说,这套事件也让排查生成失败变得简单了很多,因为问题发生在哪个阶段会更加清楚。
增加 React 项目支持,也遇到了真实的构建问题
项目原本支持 HTML、原生多文件和 Vue 项目,后来我又增加了 React 项目支持。用户不需要手动选择所有情况,后端会先根据需求判断合适的生成类型,再调用对应的系统提示词、文件工具和构建器。
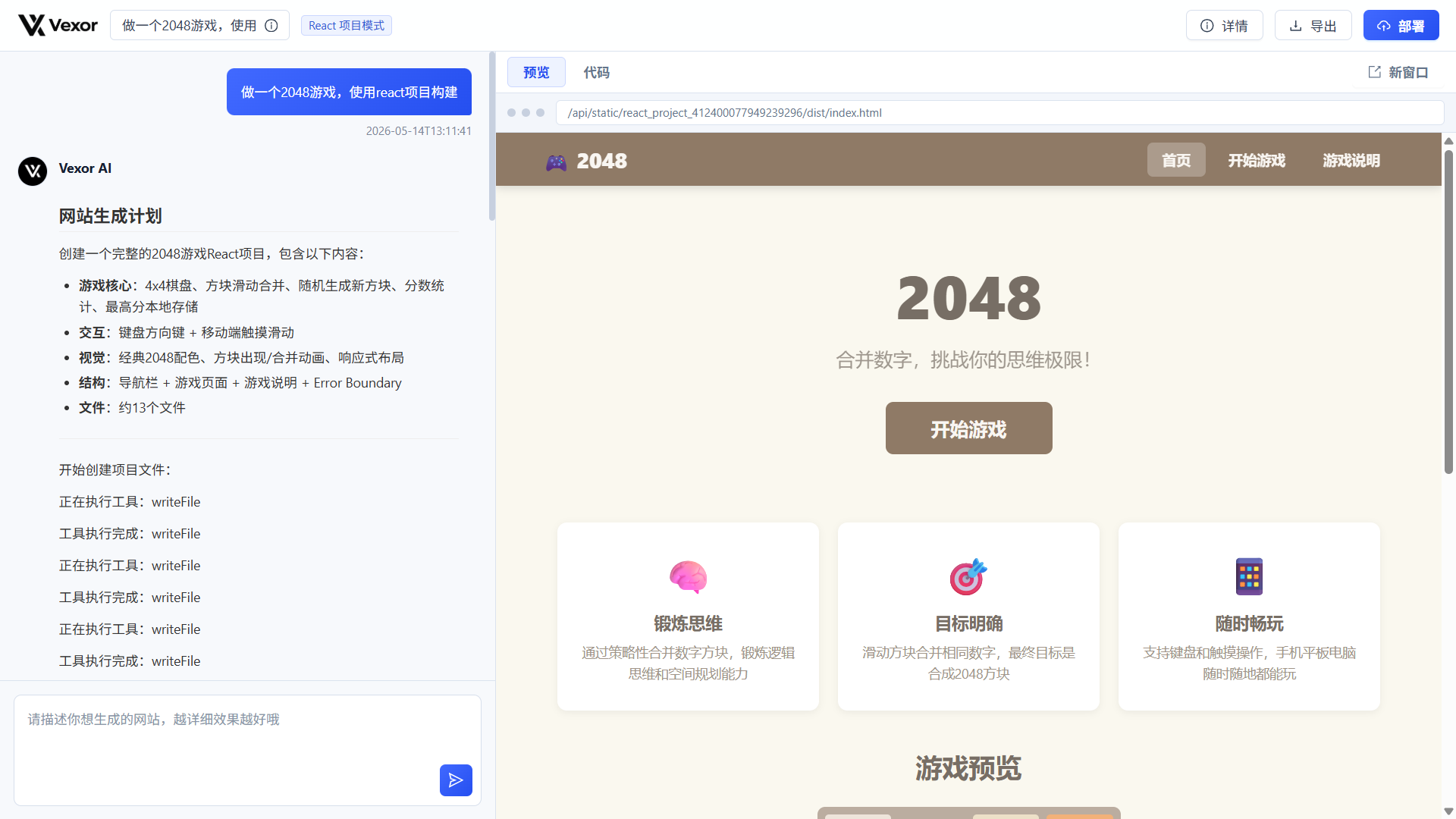
AI 生成并构建完成的 React 2048 项目,可以直接在右侧预览。
React 支持涉及的主要目录包括:
vexor-backend/src/main/resources/prompt/codegen-react-project-system-prompt.txt
vexor-backend/src/main/java/com/xm/vexorbackend/core/builder/ReactProjectBuilder.java
vexor-backend/src/main/java/com/xm/vexorbackend/ai/tools/
Vue 和 React 与普通 HTML 最大的区别,是代码生成完成并不代表可以立即预览。后端还需要在项目目录中执行 npm install 和 npm run build,确认生成了 dist 目录后,才能提供静态预览。
这部分在本地开发时比较顺利,但部署到 2 核 2G 的服务器后,问题很快出现了。
有一次生产环境中 AI 生成的数学函数网站 React 项目引入了体积较大的 mathjs。安装依赖和打包过程持续占用 CPU 与内存,不仅连续触发构建超时,还让同一台机器上的 Spring Boot、Redis 和 MySQL 得不到足够资源,最终导致整个后端响应异常。
针对这个问题,我对 React 构建流程做了几项调整:
- 将安装和构建超时时间都增加到 10 分钟
- 通过
NODE_OPTIONS=--max-old-space-size=512限制 Node.js 内存 - 构建完成后检查
dist目录是否真的生成 - 兼容 Windows 下的
npm.cmd
这些调整缓解了当前服务器上的问题,但并没有彻底解决资源竞争。AI 生成项目和普通业务接口不太一样,它会执行依赖和复杂度都不完全可控的构建任务,资源消耗可能突然变大。长期来看,构建任务最好进入独立队列,并与业务服务分开部署。
上线以后,开始处理稳定性问题
本地开发时,请求基本都来自自己,很多问题不容易暴露。项目真正部署到公网后,创建应用、生成代码、部署、下载和文生图等接口都有可能被连续调用,而这些操作背后的成本差别很大。
为此,我在后端增加了基于 Redisson 的注解式限流。接口可以按照 API、用户或 IP 三种维度设置频率,例如限制单个用户短时间内创建应用和部署的次数,也可以按照 IP 控制文生图调用量。
@RateLimit(
limitType = RateLimitType.USER,
rate = 2,
rateInterval = 600,
message = "部署过于频繁,请10分钟后再试"
)
使用注解的好处是限制规则能够直接写在接口旁边,不需要在每个 Controller 中重复处理。创建应用、提示词优化、代码生成、部署、下载和文生图接口目前都根据实际消耗设置了不同规则。
除了限流,最近几次修改还处理了全局异常返回、网页截图和 AI 流式响应中的稳定性问题。它们没有新页面那么直观,但上线以后,错误能否被正确捕获、连接能否正常结束、服务会不会被单个高消耗任务拖垮,反而更影响实际体验。
从 ZeroCode 改名为 Vexor
项目最开始直接使用 ZeroCode 作为名称。随着界面和功能逐渐形成自己的样子,所以我又使用 ChatGPT 重新设计了 Logo,并把项目名称改成了 Vexor。前后端包名、页面文案、图标和相关配置也做了对应调整。
![]()
不过线上域名目前仍然使用:
域名暂时保留了项目最开始的名字,一方面避免重新调整已经部署好的地址,另一方面也算记录了它从项目一路改造过来的过程。
最后
这次改造让我感受最深的一点是:把功能做出来和把项目真正上线,中间还有很长一段距离。
模型调用只是整个流程中的一部分。用户能不能理解当前生成进度、代码应该保存在哪里、文件接口是否安全、构建任务会不会拖垮服务器、失败时能不能给出明确提示,这些看起来不那么亮眼的小细节,最后都会直接影响项目是否真的可用。
目前 Vexor 还在继续完善,可视化编辑、构建隔离、生成质量和部署流程都有优化空间。不过相比最初只能生成和预览代码的版本,它现在已经更接近一个可以实际使用的 AI 应用生成平台。
如果你对它感兴趣,可以直接打开 zerocode.1000ye.top 体验,也欢迎查看 GitHub 后端仓库 和 GitHub 前端仓库。
